作业 6: 嵌套字典、文件读取与类
本周你将练习一些新主题,同时巩固嵌套字典和文件读取等旧知识,这对当前作业和作业6都很有帮助。
🌍 心态可视化项目
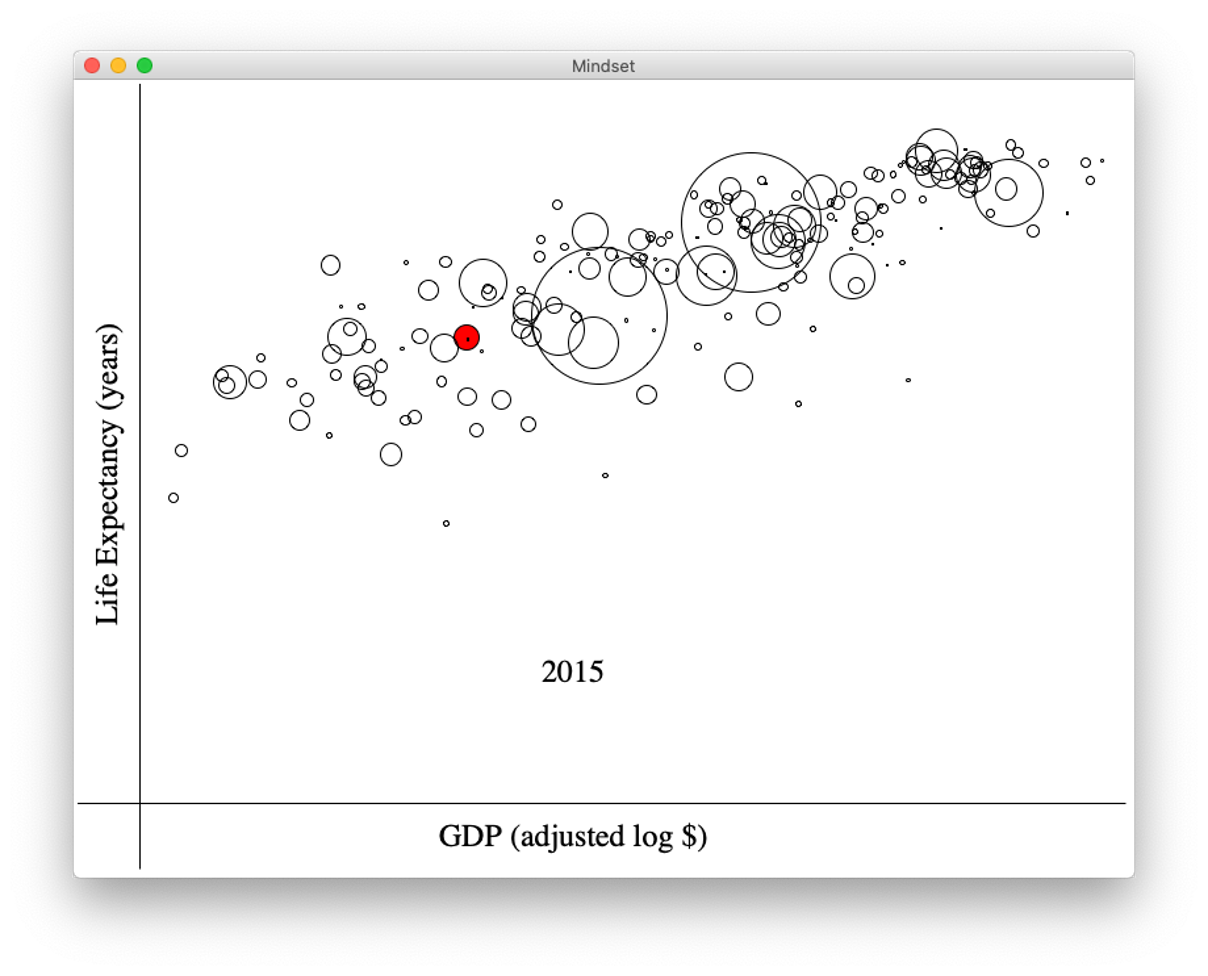
在过去的两个世纪里,人类见证了健康和财富的巨大转变,重塑了全球格局。1809年,预期寿命不到40岁,平均收入难以超过3000美元。但二战后,进步加速。
受Hans Rosling分析的启发,我们的目标是可视化200个国家的预期寿命和人均收入的演变。我们的旅程始于1809年,描绘了全球健康和经济状况的逐步改善。Rosling的数据表明,西方与非西方国家的差距正在缩小,世界趋于融合。他的主要观点是,世界上不再有两种类型的国家,发达国家和发展中国家的旧划分已被社会和经济发展水平的连续体所取代。
红色气泡表示我们在可视化中关注的国家。
我们的目标是复现这种可视化,将任务分为两步:1. 添加数据点,2. 绘制图形。
📝 第1部分:数据处理
你需要实现一个函数,帮助我们将新数据点添加到可视化中。该函数接收包含GDP、人口和预期寿命等数据的CSV文件,目标是生成一个JSON文件mindset.json,以字典格式存储数据。每一年在JSON字典中是一个键,对应值为该年每个国家的数据。例如:
{
"1800": {
"Afghanistan": {"life": 28.21, "pop": 3280000, "gdp": 603.0},
"Albania": {"life": 28.2, "pop": 3284351, "gdp": 604.0},
...
"Zimbabwe": {"life": 20.8, "pop": 12226542, "gdp": 98.0}
},
...
}该函数处理名为<key>.csv的CSV文件,其中key可以是“life”、“pop”或“gdp”。每个文件每行格式为国家名,后跟每年的数据。例如:
Afghanistan,28.21,28.2,28.1 ...写完后,检查生成的mindset.json是否正确!
📊 第2部分:数据可视化
接下来,我们将用图形技能可视化刚刚处理的数据。首先,加载刚创建的JSON文件。起始代码会提示用户输入要跟踪的国家,并将其保存到变量track_country。我们还为你绘制了画布、坐标轴和动画。
canvas = make_canvas(CANVAS_WIDTH, CANVAS_HEIGHT, 'Mindset')
# 遍历每一年
for year in range(START_YEAR, END_YEAR + 1):
clear_canvas(canvas)
draw_graph_background(canvas)
draw_year_text(canvas, year)
# TODO: 从数据中提取该年数据
year_data = 0
plot_year_bubbles(canvas, year_data, track_country)
# 动画
canvas.update()
if year % 10 == 0:
input('Enter to continue')
canvas.mainloop()你的任务是:从数据中提取年份数据,并实现plot_year_bubbles函数,在画布上绘制每个国家该年的气泡:
def plot_year_bubbles(canvas, year_data, track_country):
# ...🧑💻 类的追踪与字典实现
回顾我们在讲座中一起写过的字典类:
INITIAL_SIZE = 10000
"""
一个简单的Python字典实现。核心思想:维护一个大列表,用哈希将key映射到索引。
"""
class Dictionary:
def __init__(self):
self.data = []
for i in range(INITIAL_SIZE):
self.data.append(None)
def set(self, key, value):
index = self.key_to_index(key)
self.data[index] = value
def get(self, key):
index = self.key_to_index(key)
return self.data[index]
def key_to_index(self, key):
data_size = len(self.data)
hash_value = hash(key)
return hash_value % data_size跟踪下面的代码并将输出打印到终端:
def main():
animal_sounds = Dictionary()
animal_sounds.set("Dog", "Woof")
populate(animal_sounds)
print(animal_sounds.get("Dog"))
print(animal_sounds.get("Cat"))
print(animal_sounds.get("Horse"))
def populate(sounds):
# 变异
sounds.set("Horse", "Neigh")
print(sounds.get("Horse"))
print(sounds.get("Dog"))
# 重新赋值
sounds = Dictionary()
# 变异
sounds.set("Cat", "Meow")
print(sounds.get("Cat"))
print(sounds.get("Horse"))
print(sounds.get("Dog"))
if __name__ == '__main__':
main()⏳开始你的编程之旅吧!